Australian Centre for Ecogenomics // University of Salamanca
September 27, 2023
Why to parallelize
Have you ever noticed that RStudio never reaches 100% CPU usage even when running a very demanding task?
R runs only on a single thread on the CPU by default
Is it the most efficient way to run functions?
- Independent operations
Parallelization in R
It is possible to parallelize processes in R using specialized packages.
parallel
- Most used package
- Part of r-core.
Cores in our PC and management of clusters
Basic concepts
- Core: an individual processing unit within a CPU
- Cluster: R background sessions that allows parallelization of processes.
Methods of Paralleization
There are two main ways in which code can be parallelized, via sockets or via forking
- Socket approach: launches a new version of R on each core
- Forking approach: copies the entire current version of R and moves it to a new core
Socket pros and cons
- Pros
- Works on every OS.
- Each process on each node are 100% independent.
- Cons
- Each process is unique so it will be slower
- Variables and packages must be imported to the created cores.
- More complicated to implement.
Forking pros and cons1
- Pros
- Faster.
- Not necessary to import the variables and packages.
- Relatively easier to implement.
- Cons
- Does NOT work on Windows
- Processes are not totally independent, and can cause weird behaviors when runned in RStudio .
parallel and apply
parallel is designed to work with functions, and it is analogous to the use of functions like apply, as well as its derivatives lapply and sapply
| apply | parallel | INPUT | OUTPUT |
|---|---|---|---|
| apply | parApply (parRapply, parCapply)1 | data.frame, matrix | vector, list, array |
| sapply | parSapply | List, vector, data.frame | vector/matrix |
| lapply | parLapply | List, vector, data.frame | list |
foreach
foreach is a package designed for looping. It also allows to combine results in diferent formats.
foreach1
By itself, foreach do not parallelize, but it can be combined with parallel and doParallel to allow paralellization
[1] 2.718282 7.389056Example
Determine which numbers on a sample are primes
Function:
isprime <- function(num){
prime=TRUE
i=2 #I need to start from 2, as prime numbers can only be divided by 1 and themselves.
while(i<num){ #The while loop will continue running as long as the value of 'i' is less than the specified number
if ((num %% i) == 0){ #The '%%' operator calculates the remainder when our number is divided by 'i.' If the remainder is 0, it will terminate the loop
prime = FALSE
break
}
i <- i+1
}
return(prime)
}data (10,000 numbers):
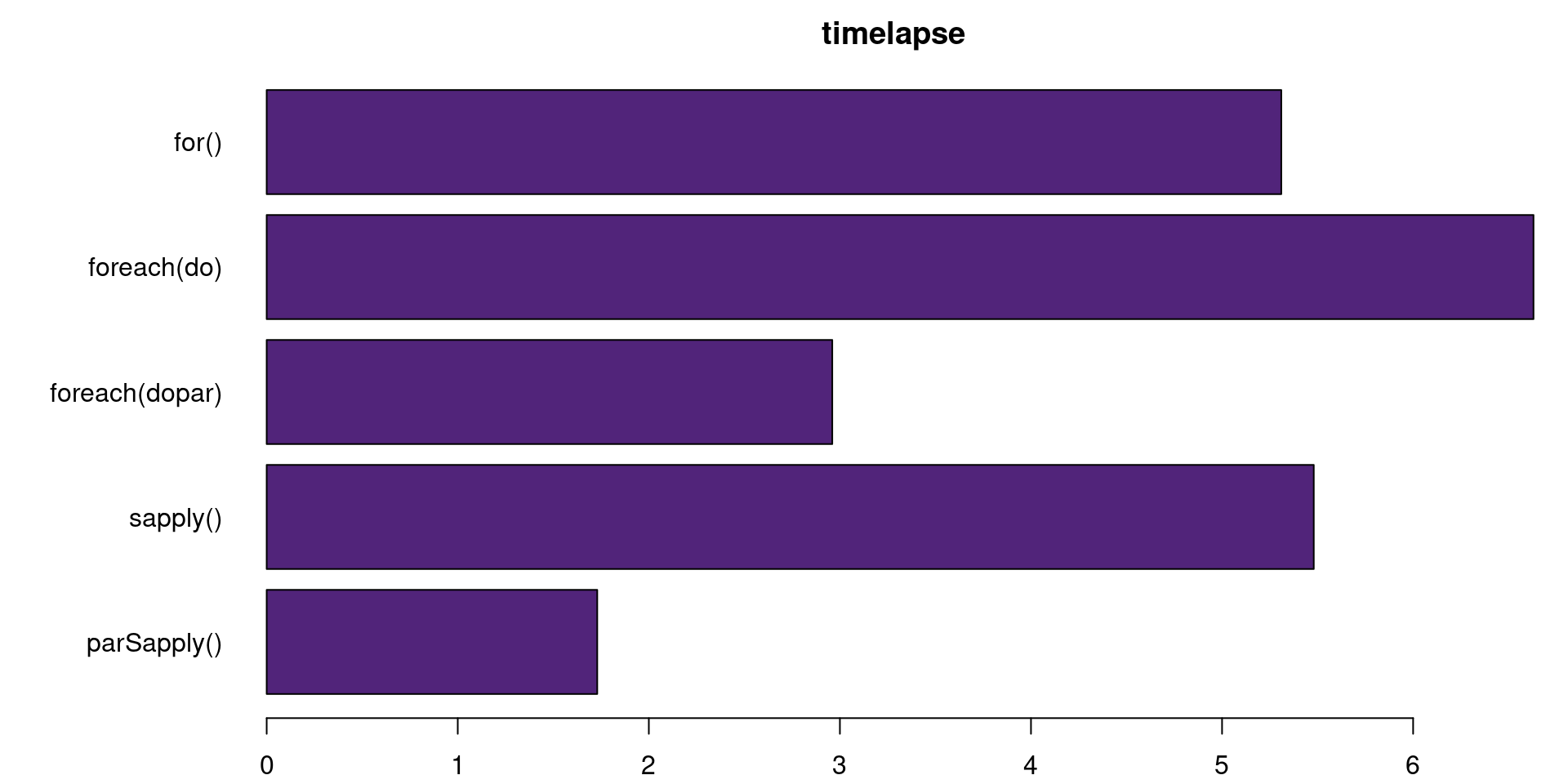
for1
[1] "Time difference of 5.308078 secs"foreach1
[1] "Time difference of 6.629166 secs"foreach parallelized
library(parallel)
library(foreach)
library(doParallel)
cores <- detectCores()
clust <- parallel::makeCluster(cores)
registerDoParallel(clust)
primes_par_fe <- foreach(i = 1:length(listnumbers), .combine="c") %dopar% {
isprime(listnumbers[i])
}
result_par_fe<-data.frame(number=listnumbers, is_prime=primes_par_fe)
parallel::stopCluster(cl = clust) [1] "Time difference of 2.964536 secs"sapply 1
[1] "Time difference of 5.478974 secs"parSapply
[1] "Time difference of 1.725008 secs"Has the processing time improved?